Topics in Artificial Intelligence - Part 2 - Machine Learning (Somewhat Technical)

- Basic Information Concerning Machine Learning
Machine learning is a subfield of artificial intelligence (AI) that focuses on the development of algorithms and statistical models that enable computers to automatically improve their performance on a specific task through experience. It allows computers to learn from data without being explicitly programmed.
The basic idea behind machine learning is to build algorithms that can learn patterns and relationships in data, and then use that knowledge to make predictions or take actions. There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
Supervised learning involves training a model on a labeled dataset, where the target output is known. The goal is to learn the mapping between input and output, so that the model can make predictions on new, unseen data. Examples of supervised learning problems include image classification, speech recognition, and regression analysis.
Unsupervised learning, on the other hand, involves training a model on an unlabeled dataset, where the target output is unknown. The goal is to discover structure in the data, such as clustering similar data points together or finding low-dimensional representations. Examples of unsupervised learning problems include dimensionality reduction and anomaly detection.
Reinforcement learning involves training an agent to make a sequence of decisions in an environment, in order to maximize a reward signal. The agent learns by observing the consequences of its actions and adjusting its strategy accordingly. Reinforcement learning is used in problems such as robotics and game playing.
Machine learning algorithms can be implemented using a variety of tools and techniques, including decision trees, random forests, support vector machines, neural networks, deep learning, and many others. The choice of algorithm depends on the problem being solved, the type and quality of the data, and the computational resources available.
Overall, machine learning has become a critical technology for solving a wide range of problems, from recognizing objects in images to optimizing supply chains to playing games at superhuman levels. It has been widely adopted in industries such as healthcare, finance, retail, and many others, and is poised to continue to play a major role in shaping the future of AI and technology.
Three Major Types of Machine Learning
Supervised Learning
Supervised learning is a type of machine learning that involves training a model on labeled data, where the target output is known. The goal of supervised learning is to learn the mapping between input features and output labels, so that the model can make accurate predictions on new, unseen data.
Supervised learning algorithms are trained on a labeled dataset, where each example in the dataset consists of an input feature vector and a corresponding output label. The algorithm's task is to learn the underlying relationship between the input features and the output labels.
Once the model has been trained, it can be used to make predictions on new, unseen examples by using the learned mapping. For example, in a classification problem, the model takes an input feature vector and predicts a class label. In a regression problem, the model takes an input feature vector and predicts a continuous value.
There are many different algorithms that can be used for supervised learning, including linear regression, logistic regression, decision trees, random forests, support vector machines (SVMs), and neural networks. The choice of algorithm depends on the specific problem being solved, the type and quality of the data, and the computational resources available.
One key aspect of supervised learning is the quality of the labeled data used to train the model. If the training data is noisy or contains outliers, the model may not learn the correct mapping between input features and output labels. In some cases, the training data may be biased, leading to a model that does not generalize well to new, unseen data.
To overcome these challenges, techniques such as cross-validation and regularization are often used to improve the quality of the model. Cross-validation involves splitting the training data into multiple subsets, training the model on different subsets, and evaluating its performance on the remaining data. This allows for an estimate of the model's generalization performance, and can help prevent overfitting to the training data. Regularization involves adding a penalty term to the model's objective function to reduce the complexity of the model and prevent overfitting.
- Unsupervised Learning
Unsupervised learning is a type of machine learning that involves training a model on unlabeled data, where the target output is unknown. The goal of unsupervised learning is to discover structure in the data, such as finding hidden patterns, grouping similar data points together, or finding low-dimensional representations of the data.
Unlike supervised learning, unsupervised learning algorithms do not have a specific target variable to predict. Instead, they analyze the input data to identify patterns and relationships that are not immediately apparent. This can be used for a variety of purposes, such as clustering data into groups, reducing the dimensionality of the data, or finding anomalies in the data.
There are several different types of unsupervised learning algorithms, including clustering algorithms, dimensionality reduction algorithms, and anomaly detection algorithms. Clustering algorithms, such as k-means or hierarchical clustering, aim to divide the data into groups (clusters) based on similarity. Dimensionality reduction algorithms, such as principal component analysis (PCA) or t-SNE, aim to reduce the number of dimensions in the data while preserving as much information as possible. Anomaly detection algorithms aim to identify data points that are different from the majority of the data, and are used for tasks such as fraud detection or detecting machine failures.
Unsupervised learning algorithms can be implemented using a variety of tools and techniques, including linear algebra, probability theory, and optimization. The choice of algorithm depends on the specific problem being solved, the type and quality of the data, and the computational resources available.
One key aspect of unsupervised learning is that it is unsupervised, meaning that there is no ground truth to evaluate the performance of the model. Instead, the quality of the model is evaluated using techniques such as visualization, clustering metrics, or reconstruction error.
- Reinforcement Learning
Reinforcement learning is a type of machine learning that focuses on training agents to make decisions in an environment in order to maximize a reward signal. Unlike supervised learning, where the goal is to learn a mapping from inputs to outputs, and unsupervised learning, where the goal is to discover structure in the data, the goal of reinforcement learning is to learn a policy, which is a mapping from states to actions.
In a reinforcement learning scenario, an agent interacts with an environment by taking actions and receiving observations and rewards. The agent's goal is to learn a policy that maximizes the expected cumulative reward over time. The policy is updated iteratively as the agent gains more experience in the environment.
Reinforcement learning algorithms can be divided into two categories: value-based methods and policy-based methods. Value-based methods, such as Q-learning, aim to estimate the value of taking a particular action in a particular state. Policy-based methods, such as policy gradients, directly learn a policy by optimizing the expected reward with respect to the policy parameters.
Reinforcement learning has been applied to a wide range of problems, including game playing, robot control, and recommendation systems. One of the key advantages of reinforcement learning is that it can handle problems with delayed rewards and complex, high-dimensional environments.
One key challenge in reinforcement learning is finding a good balance between exploration and exploitation. The agent needs to explore the environment in order to learn about it, but at the same time it needs to exploit its current knowledge to maximize the reward. Techniques such as epsilon-greedy exploration and Thompson sampling can be used to strike a balance between exploration and exploitation.
Major Tools for Implementation of Machine Learning
Decision Trees
Decision trees are a popular and widely used machine learning algorithm for both supervised learning and unsupervised learning tasks. They are called decision trees because they resemble a tree-like structure, where each internal node represents a decision, each branch represents an outcome of that decision, and each leaf node represents a prediction.
In the context of supervised learning, decision trees are used for classification and regression tasks. For classification tasks, the goal is to predict a categorical output variable based on input features. For regression tasks, the goal is to predict a continuous output variable based on input features. The prediction made by a decision tree is obtained by traversing the tree from the root node to a leaf node, making decisions at each internal node based on the input features.
The decision tree algorithm starts by selecting the best feature to split the data at the root node. The best feature is typically selected based on a criterion such as information gain or Gini impurity (a measure of the disorder or randomness in a set of categorical items). The data is then split into two or more subsets based on the values of the selected feature. This process is repeated for each branch, recursively splitting the data into smaller subsets, until a stopping criterion is reached. The stopping criterion can be based on the size of the subset, the depth of the tree, or some other criterion.
Once the tree has been grown, it can be used to make predictions for new data points. To make a prediction, a new data point is fed into the tree and the decisions made at each node determine which branch to follow until a leaf node is reached. The prediction made by the tree is the value associated with the reached leaf node.
Decision trees have several advantages over other machine learning algorithms, including their interpretability, ability to handle both categorical and numerical data, and the ability to handle missing values and noisy data. However, decision trees can also be prone to overfitting, especially if the tree is grown too deep or if there is a large number of features. To address this issue, techniques such as pruning or ensemble methods such as random forests can be used.
- Random Forests
Random forests are a type of ensemble learning method used for both classification and regression tasks in machine learning. The idea behind random forests is to build many individual decision trees and then combine their predictions to make a final prediction. This combination of decision trees leads to a more robust and accurate prediction compared to a single decision tree.
Random forests are constructed by growing many decision trees on random subsets of the training data and features. The subsets of data used to train each tree are drawn randomly with replacement, so each tree is trained on a different set of data. This process helps to reduce overfitting, as the trees are trained on different subsets of the data and therefore are likely to have different structures. The final prediction is made by combining the predictions of the individual trees, either by a majority vote for classification tasks or by averaging the predictions for regression tasks.
One of the key features of random forests is the use of feature randomness, where a random subset of features is selected for each split in the decision tree. This helps to prevent overfitting by forcing the decision trees to consider a different subset of features for each split. This also helps to reduce the correlation between the trees, as each tree is forced to make decisions based on different subsets of the features.
Another important feature of random forests is the use of bootstrapped samples, which are samples drawn randomly with replacement from the training data. By training each tree on a different bootstrapped sample, random forests help to reduce the variance of the final prediction and increase the stability of the model.
Random forests have several advantages over single decision trees. They are more robust to overfitting, as the combination of many decision trees helps to reduce the variance of the prediction. They are also more accurate, as the combination of many decision trees can lead to a better overall prediction. Additionally, random forests are easy to interpret and implement, and they work well with a mix of numerical and categorical data.
However, random forests can be computationally expensive, as growing many decision trees can be time-consuming. They can also be difficult to interpret, as the combination of many trees can make it challenging to understand the relationships between the features and the prediction. Additionally, random forests can be sensitive to noisy or irrelevant features, so it is important to carefully preprocess the data and select the most relevant features.
- Support Vector Machines

{kind=link}
{kind=link}
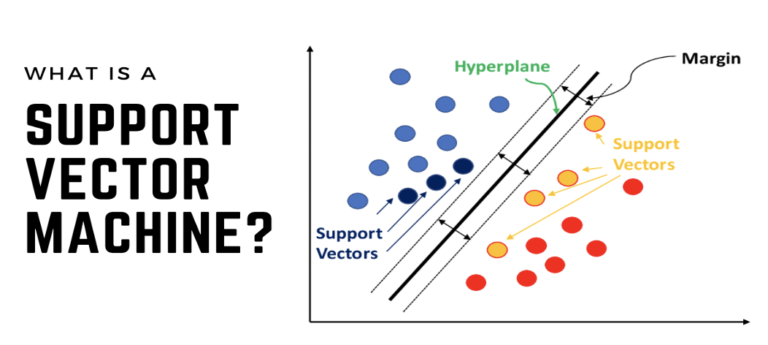
Support Vector Machines (SVMs) are a type of supervised machine learning algorithm used for classification and regression tasks. The idea behind SVMs is to find the best hyperplane that separates the data into different classes, in the case of a classification problem, or predicts a continuous target variable, in the case of a regression problem. The hyperplane is chosen so that it maximizes the margin, or the distance, between the closest data points, called support vectors, and the hyperplane.
In the case of a two-class classification problem, the goal of an SVM is to find a hyperplane that separates the data into two classes with the largest possible margin. The hyperplane is chosen such that the distances between the support vectors and the hyperplane are maximized. The support vectors are the data points closest to the hyperplane, and they determine the location and orientation of the hyperplane.
For multi-class classification problems, SVMs use a one-vs-all or one-vs-one approach to find multiple hyperplanes that separate the data into different classes. In the one-vs-all approach, a separate SVM is trained for each class, with the goal of separating that class from all the other classes. In the one-vs-one approach, a separate SVM is trained for every pair of classes, with the goal of separating those two classes from each other.
For regression problems, SVMs use a similar approach to find a hyperplane that predicts the target variable. However, instead of finding a hyperplane that separates the data into different classes, the SVM finds a hyperplane that predicts the target variable with the smallest possible prediction error.
SVMs are effective for both linear and non-linear problems, as the use of kernels (a function that defines the similarity between two data points) allows for non-linear transformations of the data into a higher-dimensional space, where a linear hyperplane can effectively separate the data. Common kernels used in SVMs include linear, polynomial, and radial basis function (RBF) kernels.
SVMs have several advantages over other machine learning algorithms. They are effective for high-dimensional data, as they are not sensitive to the curse of dimensionality. They are also robust to overfitting, as the margin maximization helps to prevent overfitting. Additionally, SVMs are well-suited for problems with small sample sizes, as they do not require a large number of data points to produce an accurate prediction.
However, SVMs also have some disadvantages. They can be computationally expensive, as the training process involves solving a quadratic optimization problem. They can also be difficult to interpret, as the hyperplane is represented in a higher-dimensional space, making it challenging to understand the relationships between the features and the prediction. Additionally, SVMs can be sensitive to the choice of kernel, as the choice of kernel can have a significant impact on the performance of the model.
- Neural Networks
Neural networks are a type of machine learning algorithm inspired by the structure and function of the human brain. They are composed of interconnected nodes, called neurons, that process information and transmit it from one layer of the network to the next. Neural networks are used to model complex non-linear relationships between inputs and outputs, making them well-suited for a wide range of tasks, such as image classification, speech recognition, and natural language processing.
A neural network is composed of several layers, including an input layer, one or more hidden layers, and an output layer. The input layer receives the input data, which is then processed by the hidden layers and transformed into a prediction or a set of probabilities for each possible output. The hidden layers use a set of weights and biases to modify the input data, and activation functions to introduce non-linearity into the processing. The output layer provides the final prediction for the input data.
The process of training a neural network involves adjusting the weights and biases in the hidden layers to minimize the difference between the predicted outputs and the actual outputs. This is done using an optimization algorithm, such as gradient descent, which updates the weights and biases in the direction of the gradient of the loss function. The loss function measures the error between the predicted outputs and the actual outputs, and its gradient provides the direction of the largest improvement in the model's performance.
One of the key advantages of neural networks is their ability to learn and make predictions based on patterns in the input data, without being explicitly programmed with a set of rules. This makes them well-suited for tasks that involve complex, non-linear relationships between inputs and outputs, where it is difficult to write explicit rules to model the relationship. Neural networks are also able to learn from large amounts of data, and they can automatically identify and extract features from the data that are relevant for making predictions.
However, neural networks can also be computationally expensive and time-consuming to train, especially for large datasets and complex models. Overfitting, where the model learns the training data too well and is unable to generalize to new data, is also a common problem in neural network models. To mitigate these challenges, techniques such as regularization, early stopping, and cross-validation can be used to improve the performance of the model.
- Deep Learning
Deep learning is a subfield of machine learning that uses artificial neural networks with multiple layers, known as deep neural networks, to model complex relationships between inputs and outputs. It builds upon traditional neural network models by adding more layers, making it possible to model more abstract and high-level representations of the data.
Deep learning algorithms are capable of automatically learning multiple levels of abstraction in the data, from simple features such as edges and shapes in images to high-level concepts such as objects and scenes. This allows them to learn highly complex and non-linear relationships between inputs and outputs, and to make accurate predictions for a wide range of tasks, including image classification, speech recognition, and natural language processing.
The training process for deep learning models involves adjusting the weights and biases in the network layers to minimize the difference between the predicted outputs and the actual outputs. The optimization algorithm used to update the weights and biases is typically a variant of gradient descent, which updates the weights in the direction of the gradient of the loss function. The loss function measures the error between the predicted outputs and the actual outputs, and its gradient provides the direction of the largest improvement in the model's performance.
One of the key advantages of deep learning is its ability to learn hierarchical representations of the data, where lower levels of the network learn simple features such as edges and shapes, and higher levels learn increasingly complex and abstract features such as objects and scenes. This allows deep learning models to learn highly abstract and useful features from large amounts of data, without the need for manual feature engineering.
Deep learning models can also be very large and computationally expensive, and they can be prone to overfitting if not properly designed and trained. To mitigate these challenges, techniques such as regularization, dropout, and early stopping can be used to improve the performance of the model. Additionally, GPUs are often used to accelerate the training process, since they are designed to perform the matrix operations required for deep learning algorithms efficiently.
- Conclusion
Machine learning is a rapidly growing field of computer science that enables computers to learn from data without being explicitly programmed. Machine learning algorithms can be broadly classified into supervised, unsupervised, and reinforced learning, each with its own strengths and weaknesses.
In summary, machine learning is a powerful tool for extracting insights from data and making predictions. With its growing popularity, it is likely to have a significant impact on many industries, from healthcare to finance to retail. Understanding the different types of machine learning algorithms and the available implementation tools is essential for anyone looking to get involved in this exciting field.
Posted Using LeoFinance Beta