Simulation des détecteurs géants du Grand Collisionneur de Hadrons du CERN
For my English-speaking readership, the present post is a French adaptation of this post, written last Monday, in which I discuss a recent proposal for a detector simulator for particle colliders.
Au moment où la situation chaotique du boulot commençait à se calmer, voilà la COVID qui débarque à la maison ! Parfois, je me demande quand j’aurai le droit de souffler… Du coup, pour me relaxer, voici un (plus ou moins) petit post détaillant l’une de mes publications scientifiques de 2021. Avec deux collaborateurs, nous avons proposé un nouvel outil permettant de simuler des détecteurs tels que ceux utilisés dans les expériences des collisionneurs de particules (comme le Grand Collisionneur de Hadrons, le LHC, du CERN).
Comme d’habitude, j’invite celles et ceux pour qui un tout petit peu de physique des particules par semaine est suffisant à finir de lire cette section avant de passer au résumé de fin de post contenant les grandes lignes du travail discuté aujourd’hui. Pour les autres, préparez-vous à 10 minutes de lecture qui j’espère vous intéressera.
Ce post est en continuation de deux blogs antérieurs discutant les simulations pour les collisionneurs de particules (ici et là). Après avoir discuté ce qu’il se passait dans une collision de particules et la façon de simuler cela sur des ordinateurs tels que ceux que l’on peut trouver dans le commerce (clin d’œil à @bambukah dont l’ordi est à l’agonie), je m’attaque aujourd’hui à la simulation des effets des détecteurs tels que ceux que l’on peut trouver autour du LHC.

[Crédits: Image originale de from geralt (Pixabay)]
Les collisions de particules en 5 minutes
Comment détaillé dans ce blog, une collision de particules peut se découper en plusieurs sous-processus que l’on peut considérer un par un. Cela offre l’avantage de pouvoir concevoir des outils de simulation dédiés chacun à une tâche bien précise.
Au centre de la collision se trouve ce qui est communément appelé le processus dur. Il s’agit de l’endroit où l’énergie est la plus importante. Cela signifie que le processus dur est le processus qui va permettre la création de particules lourdes (du Modèle Standard ou hypothétiques, vu que l’on parle de simulations). Je rappelle que masse et énergie sont liées, de sorte que la production d’objets lourds demande une certaine quantité d’énergie.
Une fois produites, ces particules lourdes se désintègrent, avant d’être sujettes à l’environnement de l’interaction forte lié à un collisionneur comme celui du CERN. On parle alors de cascades partoniques et d’hadronisation, que nous allons à présent définir.
La première de ces notions (les cascades partoniques) implique que chaque particule produite sensible à l’interaction forte rayonne d’autres particules sensibles à l’interaction forte. Ces dernières en rayonnent alors d’autres, et ainsi de suite. À chaque étape, une particule produit effectivement deux nouvelles particules qui se partagent l’énergie de la première. Nous avons donc une diminution de l’énergie étape par étape.
Dans la figure ci-dessous, on peut voir ce processus de rayonnement en cascade en rouge. Il s’arrête lorsque l’énergie devient inférieure à un certain seuil. À ce moment, les processus d’hadronisation entrent en jeu (en vert dans la figure ci-dessous). Les particules sensibles à l’interaction forte se combinent pour former des objets composites faits de quarks et d’antiquarks, que nous appelons de façon générique des hadrons. Les exemples les plus connus sont sans doute les protons et les neutrons.
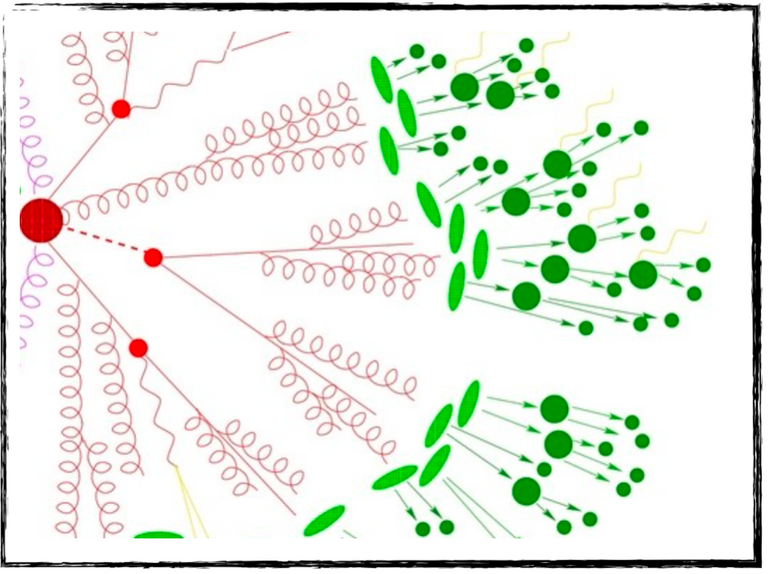
[Crédits: A Sherpa artist (image largement disponible dans la communauté des hautes énergies)]
Ainsi, à partir d’un petit nombre de particules produites dans le processus dur, on se retrouve avec une tonne de hadrons dans l’état final. C’est ici que la théorie quantique de l’interaction forte nous sauve. Elle nous dit que tous ces hadrons sont organisés de façon plutôt colinéaire à la particule rayonnante initiale. Cette notion de jets de particules est alors utilisée pour simplifier notre vision de l’état final. En pratique, on utilise un algorithme de clustering appelé algorithme de jet, afin de “clusteriser” (ou combiner pour utiliser un terme peut-être un peu moins COVID) tous les hadrons produits en un petit nombre de jets.
Dans la figure ci-dessous, on voit une coupe du détecteur CMS du LHC. On y reconnaît (si si je vous jure) un grand nombre de traces en vert, au centre, et de dépôts énergétiques en rouge et bleu, tout autour du détecteur. Tout cela provient des particules produites lors de la collision, et bien entendu des hadrons produits par cascade partonique et hadronisation. En appliquant l’algorithme de jet, on combine le tout en jets. Cette combinaison est représentées par les cones jaunes.
Dans la représentation de collision ci-dessous, on obtient trois jets avec une certaine énergie (les labels nous donnent des informations sur cela) et de l’énergie manquante (tout autant indiquée par un label) emportée soit par des neutrinos du Modèle Standard ou de la matière noire (dans le cas de théories au-delà du Modèle Standard). Nous avons pu ainsi reconstruire une image plutôt simple de ce que qu’il s’est passé dans cette collision, et nous n’avons plus à utiliser tous les dépôts énergétiques et les traces laissés par notre tonne de hadrons. On a remplacé le tout par des jets.
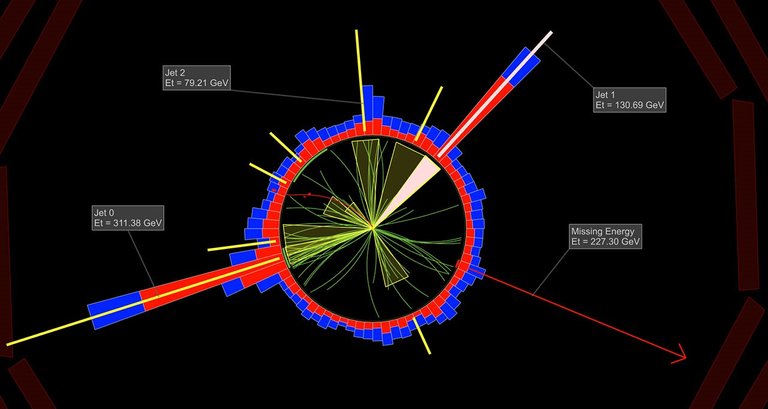
[Crédits: CMS @ CERN]
Pour résumer, peu importe ce qu’il se passe dans une collision réelle, nous finissons toujours avec un état final contenant peu d’objets : des électrons, des muons, des photons, des jets et de l’énergie manquante. On peut donc classer les collisions en fonction du nombre d’électrons, de muons, de photons, des jets et de la quantité d’énergie manquante présents dans son état final.
Mais que fait donc un détecteur ?
Dans la dernière image ci-dessus, nous avons évoqué des traces et des dépôts énergétiques dans un détecteur. En fait, toute particule produite lors d’une collision se manifeste toujours via ces traces et dépôts énergétiques. La difficulté consiste alors à connecter cela aux particules (ou objets de façon générique) qui leur ont donné naissance. Une fois cela fait, on peut associer à chaque collision un certain nombre d’objets de haut niveau (ou reconstruits) avec des propriétés bien définies.
Cela se base sur des algorithmes de reconstruction qui prennent les traces et les dépôts énergétiques en input et ressortent ces objets de haut niveau en output. Bien sûr, ceci n’est pas une science exacte et l’efficacité n’est pas de 100%. Par exemple, un électron pourrait être associé à trop peu de traces et de dépôts de bonne qualité, et ne serait donc pas récupéré par l’algorithme de reconstruction. Ou alors il pourrait être récupéré mais ses propriétés seraient mal reconstruites. Et on pourrait même concevoir un cas plus extrême ou l’électron serait reconstruit comme autre chose (par exemple un jet).
Cela nous amène naturellement aux trois grandes classes d’effets de détecteur que nous allons considérer.
- Les efficacités de reconstruction. Il s’agit de la probabilité de reconstruire un objet à partir de ses impacts dans le détecteur. Cette probabilité peut être grande ou petite en fonction des propriétés de l’objet (son énergie, sa direction, etc.).
- Le smearing (que je ne vois pas comment traduire en français). Les propriétés des objets peuvent être modifiées par les défauts de la reconstruction, et les valeurs reconstruites pourraient être ainsi plus ou moins à côté de la valeur exacte (en fonction des propriétés de l’objet).
- L’identification. On peut toujours identifier de façon correcte ou incorrecte un objet. On parle alors de bons et mauvais étiquetages, dont la fréquence dépend à nouveau des propriétés de l’objet.
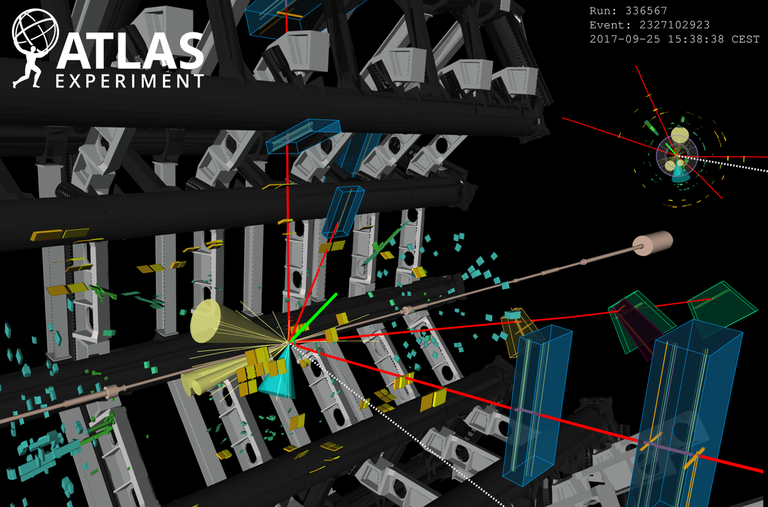
[Crédits: CERN]
Afin d’estimer toutes les probabilités liées aux effets de détecteur, les expérimentateurs se basent sur les données, sur des simulations et sur des processus très connus et très standard. Les détecteurs gigantesques du LHC sont alors simulés à l’aide du logiciel GEANT4 permettant de modéliser la géométrie du détecteur, les interactions avec sa matière constitutive et sa réponse électronique. À partir de là, les algorithmes de reconstruction mentionnés ci-dessus peuvent être mis en place.
Cependant, de telles tâches sont hors de portée pour quiconque ne fait pas partie d’une collaboration expérimentale, principalement en raison d’informations publiques nécessaires et non disponibles. De plus, même avec l’information on ne pourrait effectuer aucun calcul en dehors des gros groupes expérimentaux. Cela demande en effet une puissance de calcul incroyable.
Dans notre travail, nous avons présenté un nouveau cadre pour que tout un chacun (et toute une chacune) puisse ajouter des effets de détecteur à des simulations existantes de façon rapide et aisée.
Le framework SFS pour simuler un détecteur
Le point central de notre approche est de se baser sur l’information publique : les efficacités de reconstruction des différents objets, la résolution et comment gérer le smearing, les efficacités de bon et mauvais étiquetage, et ainsi de suite. Tout cela est en général disponible sous la forme de fonction des propriétés usuelles des objets, que nous appellerons fonctions de transfert ci-dessous.
Nous avons décidé de se baser sur ces fonctions pour décider quoi faire avec un objet après l’avoir reconstruit tel que dans un détecteur parfait. Quel smearing devons-nous faire ? Est-ce que la nature de l’objet est modifiée ? Et ainsi de suite.
Bien sûr, on obtient quelque chose d’approché. Cependant, tant que les incertitudes sont contrôlées, tout est bon ! D’une certaine façon, nous avons un gain en efficacité pour une petite perte en précision. Nous avons appelé notre outil le framework SFS (où SFS est l’acronyme de ‘simplified fast simulator’ en anglais).
De façon générale, notre point de départ consiste en des simulations au niveau hadronique (après hadronisation, comme décrit ci-dessus). Ensuite, on applique un algorithme de jet pour dégager tous les hadrons et récupérer un petit nombre de jets. Nous obtenons des événements (c’est-à-dire des collisions simulées) dont les états finaux contiennent un certain nombre d’objets de haut niveau (électrons, muons, photons, énergie manquante et jets). Mais après ?
Nous avons décidé de démarrer de la plateforme MadAnalysis5 car elle était déjà capable d’appliquer des algorithmes de jets de façon automatique. Comme il s’agit d’un package que je développe avec deux amis, dont l’un d’entre eux est d’ailleurs un auteur de l’article SFS, nous l’avons simplement généralisé pour y ajouter la possibilité d’inclure des effets de détecteur.

[Crédits: CERN]
Une fois que l’algorithme de jet a terminé son boulot, on obtient une simulation parfaite d’une collision (sans aucune dégradation due au détecteur). Ce n’est bien sûr par ce que nous voulons… Nous avons modifié le méta-langage ressemblant à du Python de MadAnalysis5 afin que toutes les fonctions de transfert mentionnées ci-dessus puisse y être implémentées aisément. Cela permet alors au programme de décider de la reconstruction ou non d’un objet, d’ajouter du smearing sur l’une ou l’autre de ses propriétés, de l’étiqueter comme il faut ou non, et le tout en fonction des propriétés de l’objet.
Par exemple, on peut facilement indiquer au code la probabilité avec laquelle un électron aux propriétés bien définies est effectivement reconstruit comme un électron. Nous pouvons ensuite dégrader ses propriétés en fonction de la résolution du détecteur. D’un point de vue pratique, l’utilisateur a seulement à lister toutes ces fonctions de transfert incorporant la façon dont fonctionne le détecteur. Dans notre travail, nous avons montré qu’on arrivait très correctement à reproduire tous les effets de détecteurs tels que CMS ou ATLAS du LHC.
Une fois tout cela effectué, MadAnalysis5 se charge de générer un code C++ associé, et de l’exécuter. Le contenu en objets de haut niveau des événements et leurs propriétés sont alors modifiés, de sorte que notre simulation “parfaite” initiale est convertie en une simulation imparfaite proche de la réalité.
De façon amusante, nous avons comparé les performances de notre outil aux codes compétiteurs. Il se trouve que nous sommes environ 50% plus rapide et le besoin en espace disque est grandement réduit. De plus, la physique est reproduite de façon totalement raisonnable. Efficacité et exactitude, que demander de mieux ?!
[Crédits: OLCF (CC BY 2.0)]
{kind=link}
La version courte ça donne quoi ?
Dans ce petit post, j’ai discuté de l’une de mes publications scientifiques récentes. Avec des collaborateurs, nous nous sommes concentrés sur les simulations de collisions de particules, et avons travaillé sur une extension d’un outil connu (MadAnalysis5, que nous développons depuis plus de 10 ans). Cet outil a à présent une nouvelle capacité permettant de simuler de façon efficace les effets d’un détecteur sur l’enregistrement d’une collision.
Notre méthode inclut les trois grandes classes d’effets de détecteur.
- Reconstruction. Toute particule qui interagit avec la matière d’un détecteur va laisser des traces et des dépôts énergétiques. Il nous faut donc pouvoir convertir ces derniers en l’objet qui les a générés. C’est ce qui s’appelle la reconstruction d’un objet, et cela a toujours une certaine probabilité de bien marcher et une certaine probabilité de foirer. On peut en effet perdre de l’information, ce qui mène à une vision un peu polluée de l’état final de la collision.
- Smearing. La résolution limitée du détecteur nous empêche de mesurer ou d’extraire la valeur réelle des propriétés des objets reconstruits. Les détecteurs ne sont en effet pas des machines parfaites et des dégradations existent.
- Identification. Reconstruire un objet est une chose, mais l’identifier correctement en est un autre. Il arrive souvent qu’un objet de type A soit reconstruit comme un objet de type B. Il nous faut inclure cette mauvaise identification dans les simulations.
Afin de prendre en compte ces effets dans MadAnalysis5, nous nous basons sur leur probabilités présentées en fonction des propriétés des objets considérés (électrons, muons, photons, énergie manquante et jets). À l’aide de ces dernières, notre framework appelé framework SFS décide si un objet donné est reconstruit ou non, si ces propriétés sont dégradées ou non et même si un objet d’une certaine nature peut être incorrectement reconstruit comme un objet d’une autre nature.
Dans notre travail, nous avons vérifié que le framework SFS donnait des prédictions en accord avec les attentes, et que le code était ainsi prêt à être utilisé pour des projets de physique. Depuis sa parution, plusieurs dizaines de travaux qui se basent sur celui-ci ont été publiés.
Voilà, je m’arrête ici et serai ravi de répondre à tout commentaire. On ne peut pas dire que mes derniers posts ont attiré foule, mais j’aurai peut-être plus de chance avec celui-ci ?
À l’avance un bon week-end ! Les vacances approchent ^^
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.
Your content has been voted as a part of Encouragement program. Keep up the good work!
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more
Congratulations @lemouth! Your post has been a top performer on the Hive blockchain and you have been rewarded with the following badge:
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz: